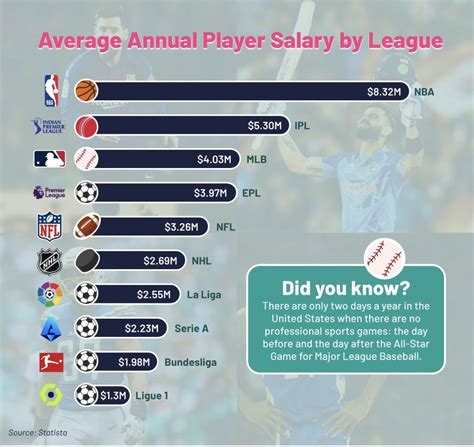
在足球这项全球最受欢迎的运动中,预测比赛结果一直是球迷和分析师津津乐道的话题,随着大数据和机器学习技术的发展,我们有了更多工具来预测比赛的进球数,本文将深入探讨如何构建一个足球比赛进球数模型,并分析其背后的数据驱动逻辑。
进球数模型的重要性 进球数模型对于足球比赛的预测至关重要,它不仅能够帮助球迷更好地理解比赛可能的走向,还能为博彩公司提供赔率设定的依据,对于球队教练和分析师来说,这样的模型可以揭示球队的进攻和防守能力,从而指导战术安排。
数据收集与预处理 构建一个有效的进球数模型,首先需要大量的历史比赛数据,这些数据包括但不限于:
数据预处理是模型构建的第一步,包括数据清洗(去除错误和不完整的数据)、特征工程(提取有用的信息)和数据标准化(使数据具有可比性)。
特征选择 在构建模型之前,我们需要确定哪些特征对进球数有显著影响,这可能包括:
模型构建 有了数据和特征后,我们可以使用多种机器学习算法来构建进球数模型,以下是一些常用的算法:
模型训练与验证 模型训练是使用历史数据来调整模型参数的过程,验证则是评估模型在未知数据上的表现,我们会将数据分为训练集和测试集,使用训练集来训练模型,然后用测试集来验证模型的准确性。
模型评估指标 评估模型的好坏,我们可以使用以下指标:
模型优化 模型优化是一个迭代的过程,可能包括调整模型参数、选择不同的算法、增加或减少特征等,目标是提高模型的预测准确性和泛化能力。
实际应用 构建好的模型可以应用于多种场景,如:
模型的局限性与挑战 尽管数据驱动的进球数模型有很多优势,但也存在一些局限性和挑战:
构建一个足球比赛进球数模型是一个复杂但有趣的过程,它不仅需要对足球有深刻的理解,还需要掌握数据分析和机器学习的技能,随着技术的不断进步,我们有理由相信,未来的进球数模型将更加精确和可靠,为足球世界带来更多的洞察和价值。
通过这篇文章,我们探讨了构建足球比赛进球数模型的全过程,从数据收集到模型评估,再到实际应用和面临的挑战,希望这能为对足球数据分析感兴趣的读者提供一些有价值的信息和启发。