亲爱的足球爱好者们,你们是否曾经想过,那些在电视屏幕上滚动的统计数据和赛后分析是如何得出的?又或者,你是否好奇过,那些专业的足球分析师是如何预测比赛结果的呢?我们就来揭开足球比赛数据模型的神秘面纱,一起探索如何构建这样一个模型,让它成为我们理解足球世界的有力工具。
想象一下,你是一位教练,正准备对阵下一场比赛,你知道对手的战术风格,也知道他们的明星球员,但如何将这些信息转化为具体的战术布置呢?这就是足球比赛数据模型的用武之地,它可以帮助我们量化球员的表现,预测比赛结果,甚至优化球队的战术安排。
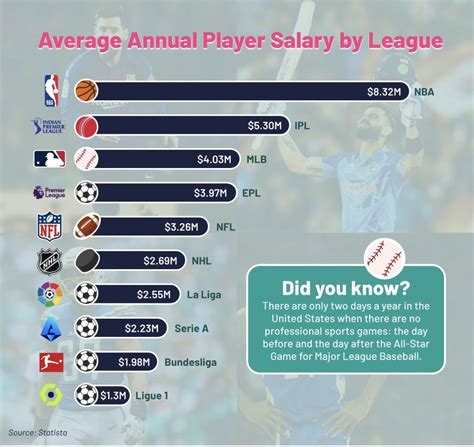
我们需要收集数据,这就像是在挖掘足球的数字宝藏,我们可以从各种来源获取数据,比如官方统计、视频分析、社交媒体等,这些数据包括但不限于球员的跑动距离、传球成功率、射门次数、控球时间等。

收集到的数据往往是杂乱无章的,我们需要进行数据清洗,这就像是在淘金,去除沙子,留下金子,我们需要剔除错误或不完整的数据,确保我们分析的准确性。
我们要从海量数据中挑选出影响比赛结果的关键因素,这就像是在烹饪一道美味的菜肴,选择哪些食材是关键,我们可能会关注球员的体能、技术、战术意识等。
有了数据和特征,我们就可以开始构建模型了,这就像是搭建一座桥梁,连接数据和预测结果,我们可以使用机器学习算法,如随机森林、神经网络等,来构建我们的模型。
模型构建完成后,我们需要通过训练和测试来优化它,这就像是在调整乐器的音调,直到它发出最美妙的音乐,我们通过比较模型预测的结果和实际比赛结果,不断调整模型参数,使其更加准确。
我们将模型应用到实际比赛中,这就像是将理论转化为实践,让我们的模型在真正的赛场上发挥作用,我们可以利用模型来预测比赛结果,分析球队表现,甚至制定战术。
足球比赛数据模型的应用场景非常广泛,它可以用于赛前分析,帮助教练制定战术;也可以用于赛后总结,分析球队的表现;甚至可以用于球员的选拔和培养,它的潜在影响是巨大的,可以提高球队的竞争力,优化资源配置,甚至改变足球比赛的面貌。
构建足球比赛数据模型是一个既复杂又有趣的过程,它需要我们像侦探一样搜集线索,像科学家一样分析数据,像艺术家一样创造模型,通过这个过程,我们不仅能够更深入地理解足球,还能够预测和影响比赛的结果,让我们一起踏上这场数字足球的冒险之旅吧!