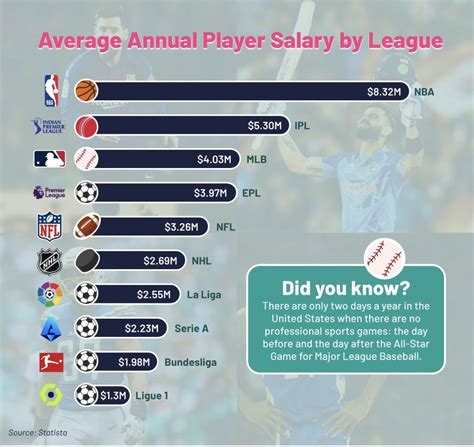
足球,这项全球最受欢迎的运动,不仅需要运动员的天赋和技巧,还需要教练的战术安排和团队的协作,随着大数据和统计分析技术的发展,足球统计模型成为了足球领域中一个越来越重要的工具,本文将带您深入了解足球统计模型的世界,探讨它们如何帮助我们更深入地理解比赛,并为球队和球迷提供实用的见解。
足球统计模型是一种应用数学和统计学原理来分析和预测足球比赛结果的工具,这些模型可以基于历史数据、球员表现、比赛环境等多个因素,来预测比赛的可能结果或者评估球员的价值,随着时间的推移,这些模型已经从简单的线性回归发展到了复杂的机器学习算法。
球员评估:通过统计模型,我们可以评估球员的表现,比如进球数、助攻数、传球成功率等,从而判断他们对球队的贡献,通过比较不同球员的统计数据,教练可以决定谁更适合首发。
战术分析:教练可以使用统计模型来分析对手的战术特点,从而制定相应的对策,如果一个对手的防守较弱,教练可能会安排更多的进攻战术。
比赛预测:通过分析历史数据和当前情况,统计模型可以预测比赛的结果,这对于博彩公司和球迷来说是一个重要的参考。
伤病预防:通过分析球员的运动习惯和历史伤病数据,统计模型可以帮助预测哪些球员更有可能受伤,从而采取预防措施。
让我们来看一个具体的例子,在2018年世界杯期间,一个名为“Opta”的足球统计公司使用其模型成功预测了法国队将赢得冠军,Opta的模型考虑了球队的进攻和防守效率、球员的个人能力、比赛的地理位置等多个因素,这个预测不仅基于统计数据,还结合了专家的分析,显示了足球统计模型的复杂性和实用性。

足球统计模型的力量在于数据,通过收集和分析大量的数据,我们可以发现一些肉眼难以察觉的模式和趋势,一项研究发现,一个球员在比赛的最后15分钟内的进球率比比赛开始时高,这可能与球员的疲劳和战术调整有关,这样的发现可以帮助教练调整战术,提高比赛的胜率。
尽管足球统计模型提供了许多有用的见解,但它们也面临着挑战,足球是一项复杂的运动,涉及许多不可预测的因素,如天气、裁判的判罚、球员的心理状态等,数据的质量和完整性也会影响模型的准确性,模型的解释和应用需要专业知识,这可能限制了它们的普及。
构建一个足球统计模型通常包括以下几个步骤:
数据收集:收集球员表现、比赛结果、天气条件等数据,这些数据可以来自官方统计、视频分析、传感器等。
数据预处理:清洗数据,去除异常值,填补缺失值,将数据转换为适合分析的格式。
特征选择:确定哪些数据特征对模型最重要,这可能需要领域知识和试错。
模型训练:使用统计或机器学习方法训练模型,这可能包括线性回归、决策树、神经网络等。
模型评估:通过交叉验证、A/B测试等方法评估模型的性能。
模型应用:将模型应用于实际问题,如球员评估、战术分析等。
随着技术的进步,足球统计模型的未来是光明的,我们可以预见,更多的球队将使用这些模型来提高比赛的表现,随着人工智能和机器学习的发展,模型将变得更加复杂和准确,随着数据的积累和分析技术的进步,我们可能会发现更多关于足球的新知识。
足球统计模型是一个强大的工具,它可以帮助我们更深入地理解足球比赛,并为球队和球迷提供实用的见解,虽然这些模型面临着挑战,但随着技术的发展,它们的潜力是巨大的,作为球迷或专业人士,了解和应用这些模型可以帮助我们更好地享受和参与这项运动。
如果您对足球统计模型感兴趣,我鼓励您探索更多的资源,您可以阅读相关的书籍和研究论文,参加在线课程,甚至尝试自己构建模型,随着您对这些模型的了解加深,您将能够更好地理解足球比赛的复杂性和美丽。
通过这篇文章,我们希望您对足球统计模型有了更深入的理解,并激发了您进一步探索这个领域的兴趣,足球统计模型不仅仅是数字和算法,它们是理解足球运动的一把钥匙,等待着我们去发现和解锁。