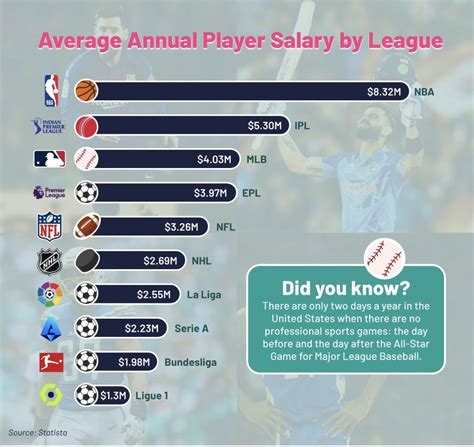
足球,作为全球最受欢迎的运动之一,其魅力不仅仅在于比赛的激烈和不可预测性,还在于球迷对于比赛结果的无限猜想,随着数据科学的发展,我们有了一种新的方式来预测足球比赛的进球数——通过建立足球进球数预测模型,本文将带你深入了解这一模型的构建过程,以及如何利用它来预测比赛得分。
足球进球数预测模型是一种基于统计学和机器学习技术的预测工具,它通过分析历史数据来预测未来比赛的进球数,这些模型可以考虑到各种因素,比如球队的进攻和防守能力、球员状态、天气条件、甚至是裁判的判罚倾向等。
数据收集:我们需要收集大量的足球比赛数据,这些数据可以包括球队的历史表现、球员的个人数据、比赛结果等,数据来源可以是公开的数据库,如Kaggle、FIFA官网等。
数据预处理:收集到的数据往往包含缺失值或异常值,需要进行清洗和预处理,我们可以填补缺失值,或者剔除那些明显不合理的数据点。
特征选择:在数据预处理之后,我们需要确定哪些特征对于预测进球数是重要的,这可能包括球队的进攻效率、防守强度、球员伤病情况等。
模型选择:我们需要选择合适的预测模型,常见的模型包括线性回归、决策树、随机森林等,选择模型时,需要考虑到模型的准确性、复杂度和可解释性。

模型训练与测试:使用历史数据对模型进行训练,并通过交叉验证等方法来测试模型的性能。
模型评估:我们需要评估模型的准确性,常用的评估指标包括均方误差(MSE)、平均绝对误差(MAE)等。
假设我们想预测即将到来的世界杯比赛中,巴西队和阿根廷队的比赛进球数,我们首先收集了两队过去几年的比赛数据,包括每场比赛的进球数、控球率、射门次数等,通过数据预处理,我们剔除了一些异常值,比如因为极端天气导致的比赛数据异常。
在特征选择阶段,我们发现控球率和射门次数是影响进球数的重要因素,我们决定将这两个特征作为模型的输入,我们选择了随机森林模型,因为它在处理这种类型数据时表现良好,并且能够提供一定的可解释性。
在模型训练阶段,我们使用了过去10年的数据来训练模型,并在最近一年的数据上进行了测试,测试结果显示,模型的预测准确率相当高,这给了我们信心。
足球进球数预测模型的实用性在于,它可以帮助球迷、博彩公司甚至是球队教练更好地理解比赛可能的结果,通过预测模型,教练可以调整战术,以提高球队的得分机会。
这种模型也有其局限性,足球比赛的结果受到许多不可预测因素的影响,比如球员的临场发挥、裁判的判罚等,预测模型只能提供一个大致的趋势,而不能完全确定比赛结果。
持续更新数据:随着时间的推移,球队的表现和球员的状态都会发生变化,定期更新模型中的数据是非常重要的。
多模型融合:不同的模型可能在不同的数据集上表现更好,考虑使用多个模型的预测结果进行融合,以提高预测的准确性。
考虑外部因素:尽管模型可以考虑到很多因素,但仍有一些外部因素可能影响比赛结果,比如天气、球员心理状态等,在预测时,可以适当考虑这些因素。
保持谨慎:预测模型只是一个工具,它不能保证100%的准确性,在使用预测结果时,应保持谨慎,并结合其他信息进行判断。
通过这篇文章,我们希望你能对足球进球数预测模型有一个更深入的了解,虽然这种模型不能预测未来的每一个细节,但它提供了一个有价值的工具,帮助我们更好地理解和预测足球比赛的结果,随着数据科学的进步,我们可以期待这些模型在未来变得更加精确和强大。