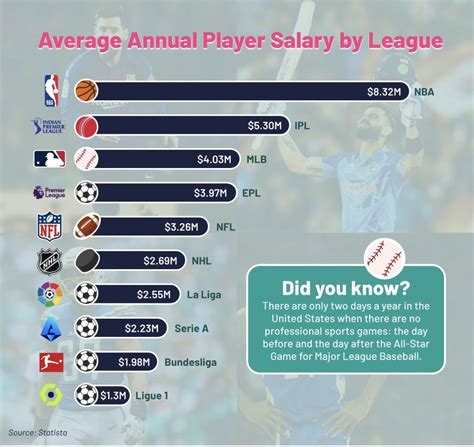
在足球这项全球最受欢迎的运动中,预测比赛结果一直是球迷和分析师们津津乐道的话题,随着大数据和机器学习技术的发展,预测模型已经成为可能,它们能够分析历史数据、球员表现、战术布局等多个维度,为预测比赛结果提供科学依据,本文将探讨如何构建一个足球比赛结果预测模型,并分析其准确性和应用前景。
构建一个足球比赛结果预测模型的第一步是数据收集,我们需要的数据包括但不限于:
1、历史比赛结果:包括胜、平、负的记录,以及进球数等。
2、球队数据:包括球队的排名、近期表现、主场或客场优势等。
3、球员数据:包括球员的出场次数、进球数、助攻数、红黄牌记录等。
4、战术数据:包括球队的常用阵型、进攻和防守策略等。
5、外部因素:如天气条件、伤病情况、赛程密度等。
这些数据可以通过公开的数据库、体育统计网站或者直接从足球俱乐部获取,数据的质量和完整性对于模型的准确性至关重要。
收集到的数据往往是原始的,需要通过特征工程来提炼出对预测结果有帮助的关键信息。
1、球队近期状态:通过计算球队最近几场比赛的得分和失分,可以评估其近期状态。
2、球员表现指数:结合球员的各项数据,可以计算出一个综合表现指数。

3、对阵历史:分析两队过去的交锋记录,找出可能的胜负规律。
4、战术匹配度:根据两队的战术特点,评估战术上的匹配度和克制关系。
特征工程是模型构建过程中最具挑战性的部分,需要数据科学家具备深厚的领域知识和创新能力。
有了清洗和特征化后的数据,接下来就是选择合适的预测模型,常用的模型包括:
1、线性回归模型:适用于预测连续变量,如进球数。
2、逻辑回归模型:适用于预测分类问题,如胜平负结果。
3、决策树和随机森林:能够处理非线性关系和高维数据。
4、神经网络:尤其是深度学习模型,能够捕捉复杂的模式和关系。
模型的选择应基于数据的特性和预测任务的需求,一旦选择了模型,就需要使用历史数据来训练模型,这个过程包括参数调优、交叉验证等步骤,以确保模型的泛化能力。
模型训练完成后,需要对其进行评估,以确定其预测准确性,常用的评估指标包括:
1、准确率:预测结果与实际结果一致的比例。
2、精确率和召回率:特别适用于分类问题,评估模型的预测能力和覆盖能力。
3、F1分数:精确率和召回率的调和平均值,用于综合评估模型性能。
如果模型的评估结果不理想,可能需要回到特征工程阶段,重新选择或构建特征,或者调整模型参数,这是一个迭代的过程,需要不断地优化以提高模型的预测能力。
一旦模型经过充分的训练和评估,就可以应用于实际的足球比赛结果预测中,模型的应用不仅可以帮助球迷和分析师做出更准确的预测,还可以为俱乐部的战术安排、球员转会等提供数据支持。
足球比赛结果预测模型也面临着一些挑战和限制:
1、数据的不确定性:足球比赛结果受多种因素影响,包括运气和偶然性,这使得模型的预测不可能达到100%的准确率。
2、数据的动态性:随着时间的推移,球队的状态、球员的表现等都会发生变化,模型需要定期更新以适应这些变化。
3、模型的透明度和可解释性:深度学习等复杂模型往往被视为“黑箱”,其预测结果难以解释,这在一定程度上限制了模型的可信度和应用范围。
尽管存在这些挑战,随着技术的不断进步和数据的日益丰富,足球比赛结果预测模型的准确性和应用前景仍然值得期待,未来的模型可能会更加注重实时数据的集成、多模态数据的融合(如视频分析、社交媒体情绪分析等),以及模型的可解释性,从而为用户提供更加全面和可靠的预测服务。
足球比赛结果预测模型是一个跨学科的领域,它结合了体育学、统计学、计算机科学等多个领域的知识,随着技术的不断发展,我们有理由相信,未来的足球比赛预测将更加科学、准确和高效,这不仅能够提升球迷的观赛体验,还能够为足球俱乐部的决策提供有力的数据支持,让我们期待数据科学在足球领域的更多创新和应用。