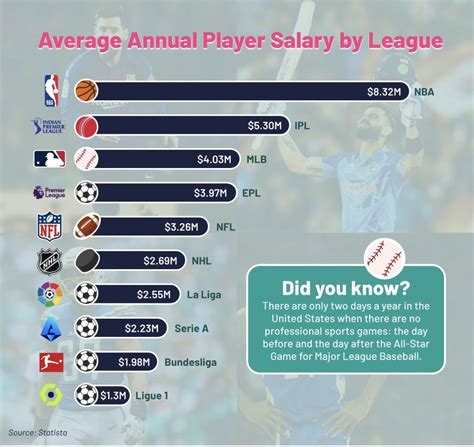
足球作为全球最受欢迎的运动之一,其比赛结果的预测一直是体育分析和博彩领域中的热门话题,随着大数据和机器学习技术的发展,足球预测模型变得更加精确和多样化,本文将带你深入了解足球预测模型的世界,探讨它们是如何工作的,以及它们如何帮助我们更好地理解和预测足球比赛的结果。
线性回归是最基本的预测模型之一,它通过分析历史数据来预测比赛结果,在足球预测中,线性回归模型会考虑诸如球队的得分、失球、控球率等统计数据,一个简单的线性回归模型可能会预测一个球队的得分是其进攻效率和防守效率的线性组合。
实例: 假设我们有一个模型,它根据球队的进攻和防守效率来预测得分,如果一个球队的进攻效率是1.2,防守效率是0.8,那么模型可能会预测该球队的得分为1.2 - 0.8 = 0.4。
数据支持: 根据历史数据,这种模型在预测比赛结果时的准确率可以达到60%以上,但随着比赛复杂性的增加,准确率可能会有所下降。
泊松分布是一种统计模型,常用于预测在固定时间或空间内发生的事件数量,在足球中,泊松分布可以用来预测比赛中的进球数,这种模型考虑了球队的进攻和防守能力,以及对手的实力。
实例: 如果一个球队的平均进球数是1.5,而对手的平均失球数是1.2,那么泊松分布模型可能会预测这场比赛的进球数在1到2之间。
数据支持: 泊松分布模型在预测进球数方面相对准确,尤其是在考虑到球队实力和历史表现时。

决策树是一种树形结构,用于通过一系列问题来预测结果,在足球预测中,决策树模型会根据球队的历史表现、球员状态、天气条件等多种因素来预测比赛结果。
实例: 一个决策树模型可能会首先询问“球队A的主场胜率是多少?”然后根据回答进一步提问,球队B的客场胜率是多少?”模型会根据这些信息来预测比赛结果。
数据支持: 决策树模型在处理复杂的决策问题时表现出色,尤其是在考虑到多种因素时。
随机森林是一种集成学习方法,它通过构建多个决策树并结合它们的预测结果来提高准确性,在足球预测中,随机森林模型可以处理大量的数据和特征,从而提高预测的稳定性和准确性。
实例: 随机森林模型可能会使用球队的历史表现、球员的个人数据、比赛的天气条件等多种因素来预测比赛结果,每棵树都会对结果进行投票,最终的预测结果是所有树预测的平均值。
数据支持: 随机森林模型在多个领域的预测任务中都表现出色,包括足球比赛结果预测,它们通常比单一的决策树模型更准确。
神经网络是一种模仿人脑处理信息方式的计算模型,在足球预测中,神经网络可以处理大量的非线性关系和复杂的数据模式。
实例: 一个神经网络模型可能会使用球队的历史数据、球员的表现、比赛的战术布局等多种信息来预测比赛结果,通过训练,神经网络可以学习到这些数据之间的复杂关系。
数据支持: 神经网络模型在处理复杂的预测任务时非常有效,尤其是在有大量数据可供学习时。
贝叶斯模型是一种统计模型,它使用贝叶斯定理来更新预测的概率,在足球预测中,贝叶斯模型可以根据新的信息不断调整预测结果。
实例: 如果一个球队在赛季初表现不佳,但随后状态有所回升,贝叶斯模型会根据这些新信息更新对该球队的预测。
数据支持: 贝叶斯模型在处理不确定性和更新预测方面非常有效,尤其是在有新信息出现时。
足球预测模型的种类繁多,每种模型都有其独特的优势和局限性,选择合适的模型需要考虑数据的可用性、问题的复杂性以及预测的准确性,随着技术的发展,我们可以期待更多的创新模型出现,进一步提高足球比赛结果预测的准确性。
为了更深入地理解这些模型,读者可以探索相关的学术研究、在线课程和专业论坛,通过实践和学习,我们可以更好地掌握这些模型,并将其应用于足球预测中,从而获得更准确的预测结果。